 快捷导航
快捷导航
1、软件无需安装,在本站下载压缩包解压到本地后点击文件即可打开程序,打开 PDF 文档,如图所示:
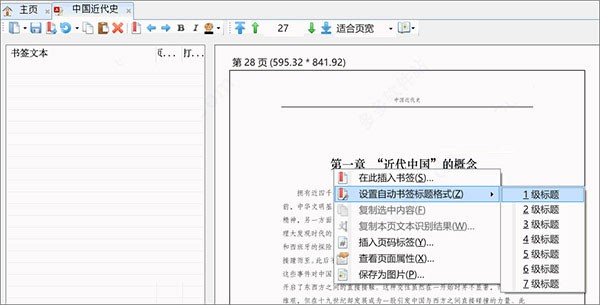
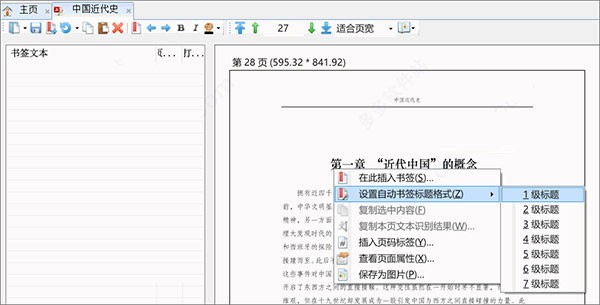
2、将鼠标移到标题文字上面,点击鼠标右键,选择“设置自动书签标题格式”命令下的标题级别。
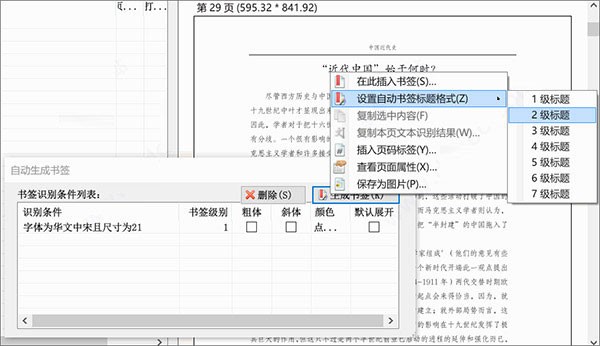
3、点击后,编辑器将弹出一个“自动生成书签”对话框,上面列出标题格式和标题级别的对应关系(调整列表项的设置可修改书签文本样式),如图所示:
4、通常,我们文档中不同级别的标题,字体样式或尺寸会有所不同。我们刚才已经告诉编辑器一级标题的字体和尺寸特征。同一个级别的标题(相同字体、相同尺寸的标题)就不要再重复标记了。然后,我们滚动页面,将鼠标移到下一个级别的标题(字体或尺寸不同的标题)上,在重复上述步骤,标定级别2的标题,如图所示:
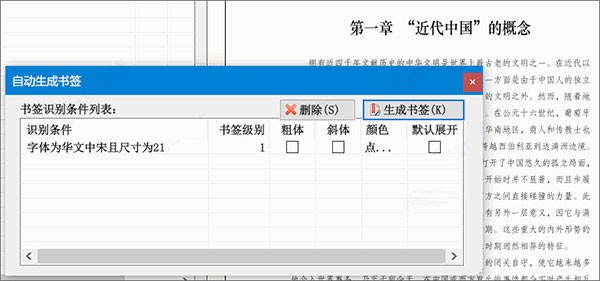
完成上述步骤后,“自动生成书签”对话框的列表会更新,第二项是新增的文本与标题映射关系。
重复上述各个步骤,标记好各级标题的样式。
然后点击“自动生成书签”对话框的“生成书签”按钮。编辑器就会自动扫描文档,按书签识别条件的样式找到对应的文本,生成各级书签标题。
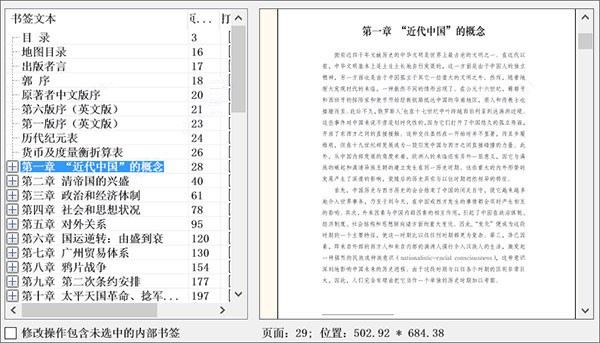
不用一分钟,就完成生成 PDF 书签的工作了,见下图:
软件信息
相关推荐
更多版本

金山PDF专业版(永久激活密钥)149MPDF软件v2025最新版
查看
Acrobat Pro DC 2025破解版940MPDF软件[绿色便携版]
查看
金山PDF专业版破解版149MPDF软件v2024最新版
查看
Adobe Acrobat Pro DC 2024破解版1.4GPDF软件[免激活版]v24.002.20736
查看
smallPDF吾爱破解版147.99MPDF软件V1.24.2无限期试用破解版
查看Acrobat2024破解版1.4GBPDF软件v24.002.20738免费版
查看
Adobe Acrobat Pro DC 2025中文破解版1.3GPDF软件
查看
PDF快速看图免费版46MPDF软件v3.8.0.23绿色版
查看
SmallPDF(PDF转换器)31.28MBPDF软件v7.2破解版
查看
讯读PDF大师破解版18MPDF软件v3.2.1.0电脑版
查看






